在某些特別的狀況下
我們無法對 CPU、記憶體建立告警
告警的目的在於有重大狀況發生
我們需要及時採取行動處理
當現有指標都無法反應現況的時候
這時候對於 Log 中的特定訊息做監控就會是很有效的方式
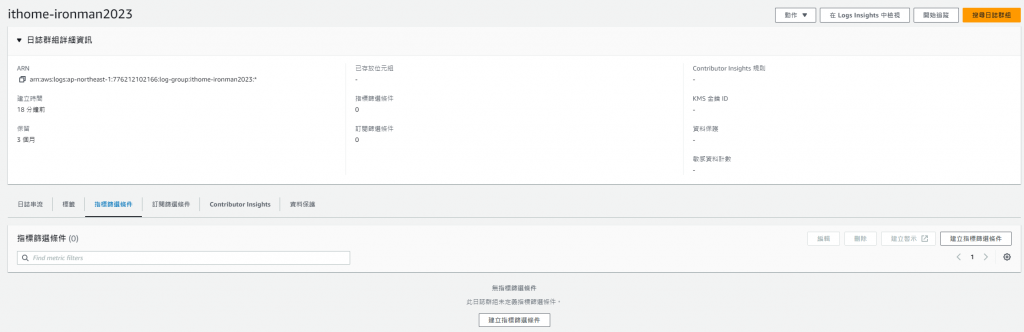
從 CloudWatch Log 中的指標篩選條件分頁
就可以進入做設定
在頁面中可能會覺得徬徨
不知道該如何做篩選指標
實際上只要輸入雙引號加上關鍵字就可以達成,e.g:"ERROR"
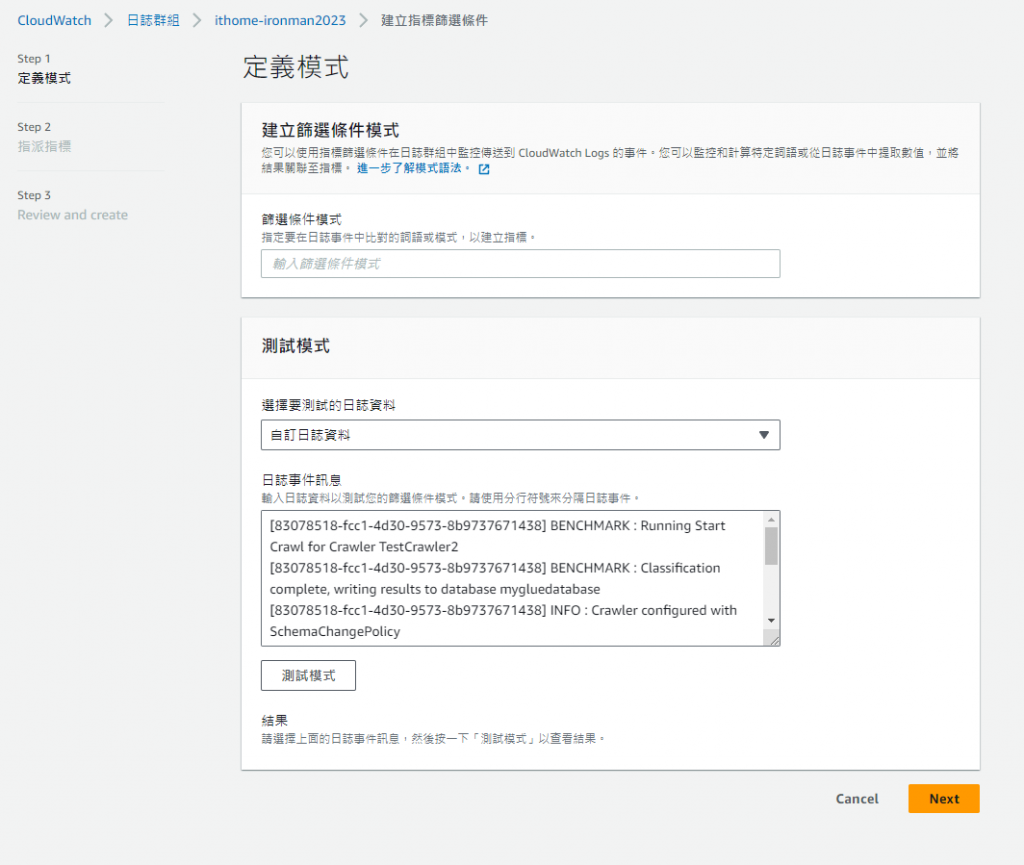
但是這樣的關鍵字篩選意義不大
有可能沒辦法抓到真的造成系統出錯的 Log
我們也可以像是 Google 篩選條件這樣
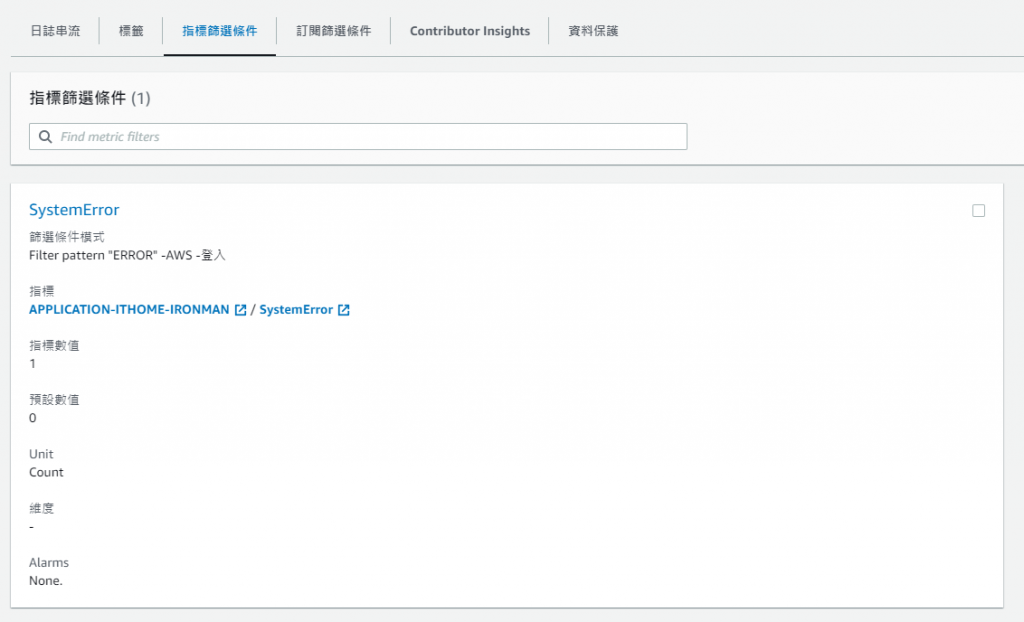
Filter pattern "ERROR" -AWS -登入
先根據關鍵字篩選 Log
然後再使用減號去除不需要的資訊來篩選
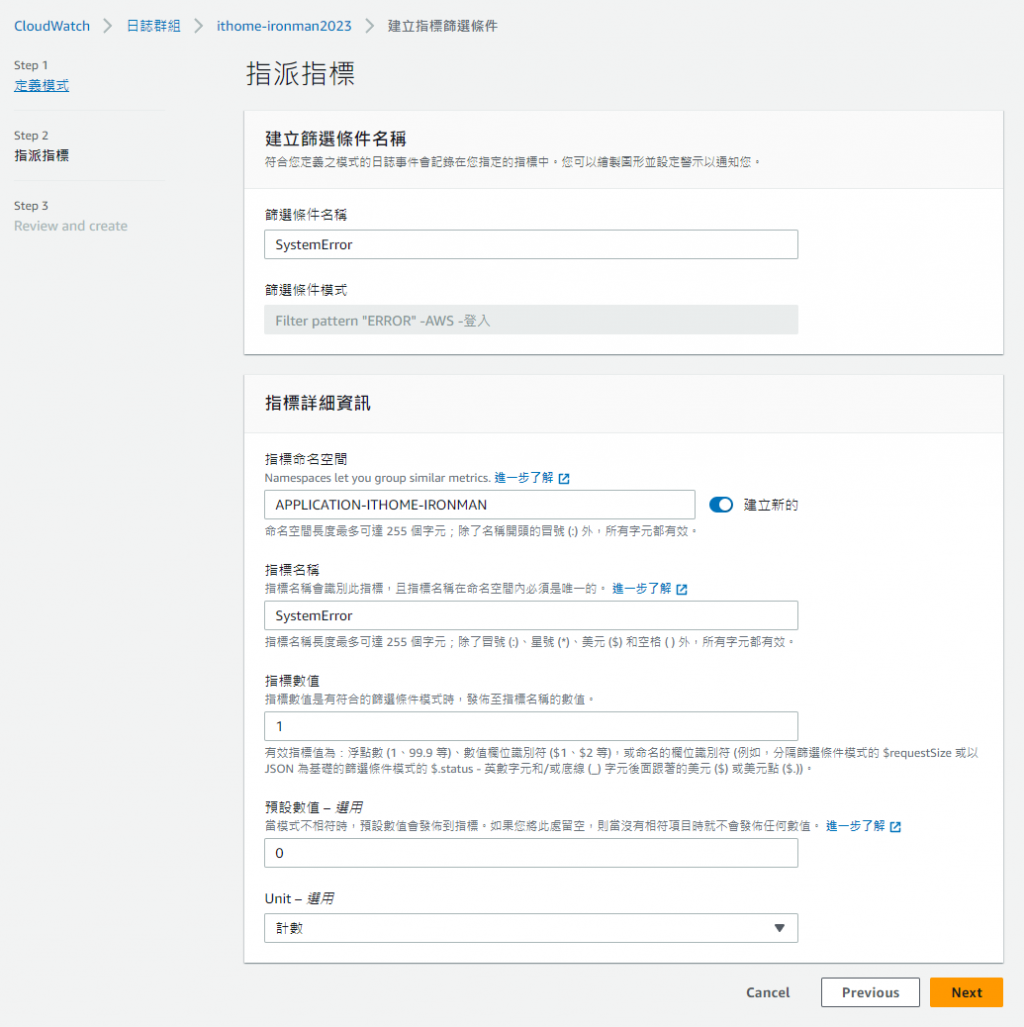
對於建立的指標
我們需要設定名字以及存放的叢集
指標數值和預設數值我們就先設定 1 和 0
因為是使用計數的方式來計算所以也只有 1 和 0
如果各位在 Log 擷取的時候有抓到其他數值也可以設定成其他單位
最後確認沒問題後就可以建立指標
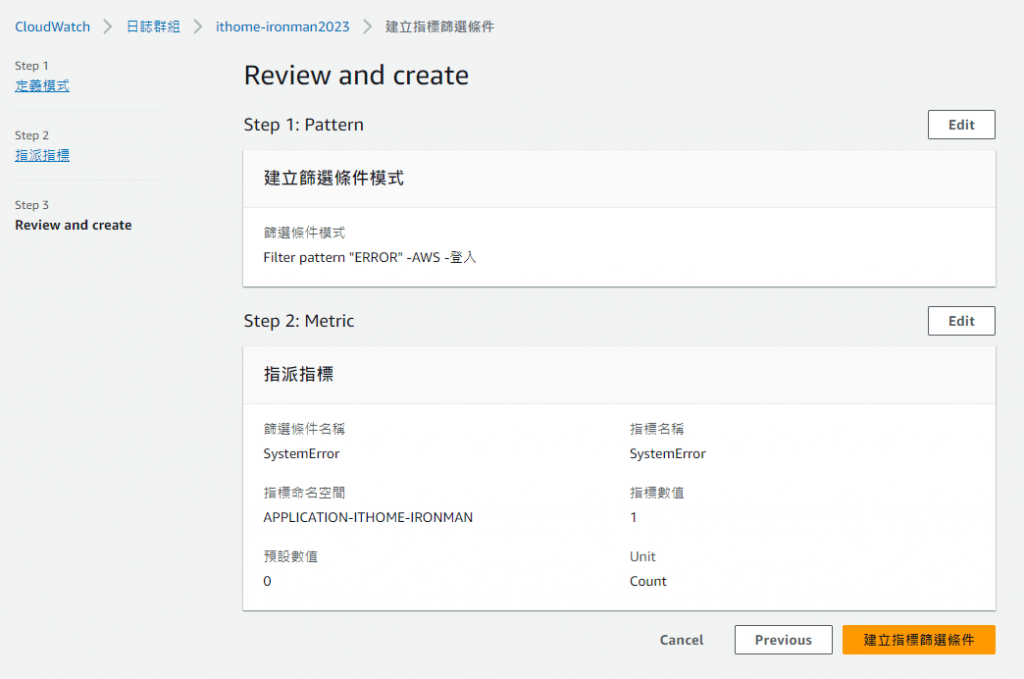
建立完指標後我們就可以看到指標篩選條件出現我們剛剛的設定
在 CloudWatch 的頁面中
靜待一段時間後也可以看到我們建立的命名空間出現在所有指標中
參考資料:

